在企业中,比程序猿还要惨的就是运维了,系统运行正常是本职工作,一旦出现性能问题或者系统故障,运维人员就要做好接锅的准备,背锅大侠的称号由此而来。
完全是自身运维的问题,那也就没什么好说的,但是还存在另外一种可能,就是框架的设计和SQL程序都是由研发人员完成,基于快速迭代的需要,DBA不可能也没有权力去把控这块,因此而导致的一些性能问题,DBA也要一起背锅就显得心累了。
其实,一个数据库的性能上限在程序设计的时候就已经决定了,我们总是期待有大咖设计出非常优良的架构,期待资深DBA人员去设计应用,而实际上90%的数据库开发人员和架构设计师并不具备资深DBA的背景,设计出来的东西往往既不规范也不符合性能要求。所以DBA的后期工作就变成了一个纯粹的人力工作。
以下用一个实例证明研发对于数据库性能的巨大影响。
--使用交叉连接构造百万计表:
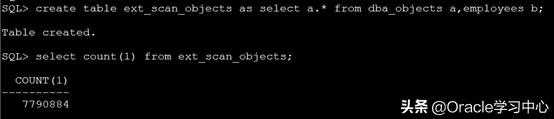
--创建同结构空表
我们的目标是将ext_scan_objects的数据插入到另外一张空表中去。
第一种方法:常规插入
为了验证时间消耗,我们打开时间显示

优点1:语法简单
优点2:对于小表、中表(数据量在千万级别左右或以下)较为合适,时间也快(本次约为83秒)
缺点1:数据量大的话,耗时长并且完成时间无法估测
致命缺点:如果数据量大到一定规模,大概率出现无法完成的情况,同时由于是一个事务一旦中途出现问题,会出现大事务长时间回滚,严重影响性能,并且重新开始,需要重新插入第一条数据
第二种方法:row by row +每行commit
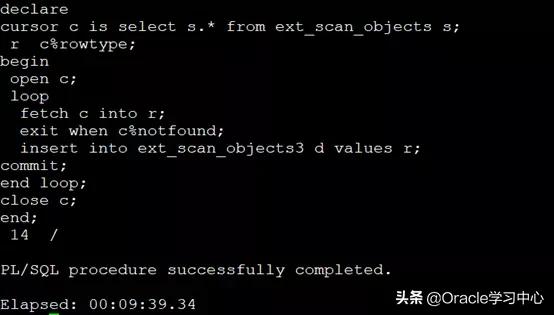
缺点1:每次都提交事务,会影响性能,处理时间可能更长(本次实验过程耗时10分钟),但不至于出现因事务过大而出现的进退两难。
缺点2:可能因频繁提交事务带来的lgwr进程繁忙导致的性能问题
优势1:出现异常中断,可以通过辅助方法判断下一次插入的位置,减少工作量
优势2:由于中途有提交事务,可以观测到插入的速度,推断出完成所需要的大致时间
第三种方法:row by row + 分批commit
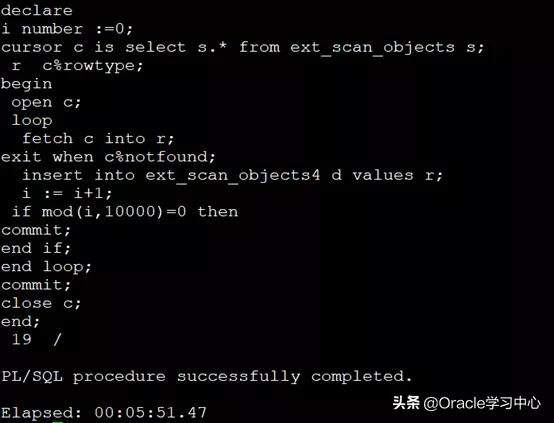
劣势1:虽然分多次提交,比方法二科学(处理时间有明显提高),但是由于仍是逐行处理,处理速度仍然没有上去
优势1:出现异常中断,可以通过辅助方法判断下一次插入的位置,减少工作量
优势2:可以观测到插入的速度,推断出完成所需要的大致时间
第四种方法:array方式
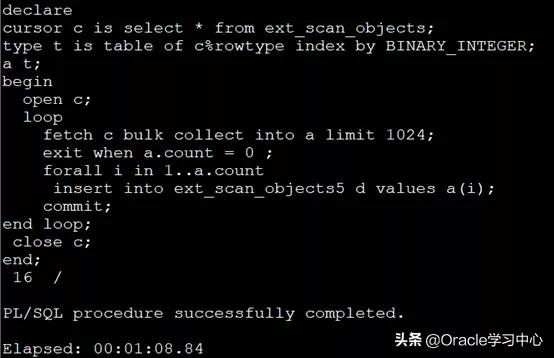
方法4不采用逐行处理,分批提交天然形成,速度大幅提升,建议使用
第五种方法:手动分拆,
insert into ext_scan_objects6 select * from ext_scan_objects where mod(object_id,5) = 0;
insert into ext_scan_objects6 select * from ext_scan_objects where mod(object_id,5) = 1;
insert into ext_scan_objects6 select * from ext_scan_objects where mod(object_id,5) = 2;
insert into ext_scan_objects6 select * from ext_scan_objects where mod(object_id,5) = 3;
insert into ext_scan_objects6 select * from ext_scan_objects where mod(object_id,5) = 4;
--一种较为"笨拙"的简单分拆方法,容易理解
--对于特大表毫无意义,并且消耗资源较多
第六种方法:set based:将要做的事情“囫囵”的告诉Oracle,该种方法性能较好
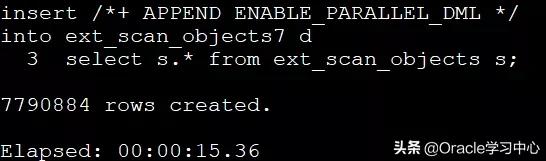
通过上面的实验证明,完成同样的任务,使用不同的方法,消耗的时间和资源都完全不一样。作为一个数据工作者,尤其是数仓工程师,相信这篇文章会给您带来一些启示。
- end -
